
Learning As We Go: Professional Learning for the Messy AI Experimentation Phase
By Kippy Smith and Erica Crane, EdD
Recently, a professional development specialist shared with us her organization's futile attempts to train the staff on their recently codified AI competencies. With AI itself and related workforce skills evolving almost daily, they could barely roll out an updated version of their competency framework before needing to revise it once again — let alone enact their training plan.
Her experience captures a mismatch at the heart of how many schools and organizations are approaching AI professional learning right now. Most AI professional learning currently offered is best suited to scaling best practices, yet we are in an experimentation phase, still learning what works through trial and error. When we design AI professional learning to match the experimentation phase we're in, we uncover the collective genius and enable transformative innovations in teaching and learning to emerge.
We're in an Experimentation Phase — not a Scaling Phase.
Despite the proliferation of online mini-modules, expert-led webinars, and "Top 10 AI Hacks" lists, we are still in an early, emergent stage of figuring out what thoughtful AI integration in education can be. Educators are experimenting — often in divergent ways, without a shared framework for what "good" looks like. This is not a problem or a deficit; this is how early-stage innovation happens.
As Rebecca Wolfe (2026) notes in her Hoover Institution research on bottom-up innovation in education, AI is "the first technology since the personal computer and internet to prompt nearly universal expectations" of "fundamental changes—for better or worse—in education, the workforce and human cognition and behavior" (p. 21). When the innovation is that significant, we shouldn't expect to have best practices neatly packaged for dissemination yet. We should expect mess, diversity of approaches, and the need to learn by trying and making mistakes.
AI is "the first technology since the personal computer and internet to prompt nearly universal expectations" of "fundamental changes—for better or worse—in education, the workforce and human cognition and behavior."
The trouble is that most formal professional development is designed for a different moment: the moment after good practices have been identified, when the goal is to spread those practices widely and reliably. That kind of PD — think expert-led webinars, static modules, "how to" workshops — may be well-suited for implementation and replication at scale. It is poorly suited for the divergent, exploratory, learn-as-we-go work that early experimentation involves. To be clear, disseminating knowledge and insights during the earliest stages of innovation is essential: creating new ways of doing things requires building knowledge. In the experimentation phase, building knowledge functions as a source of inspiration for generating fresh ideas to test out. In other words, knowledge-building sits in a larger innovation cycle. When educators have access to expert-led workshops but not the full experimentation cycle, we run the risk of fostering a compliance mindset versus a creative mindset. Educators hear "do this" versus "what do you think?"
To foster the collective learning and creative genius the education field needs during the experimentation phase, we need a different PD design.
Attributes of PD Designed for the Experimentation Phase
Professional learning that effectively facilitates collective experimentation to determine what works embodies different attributes than PD designed to scale already-defined best practices:

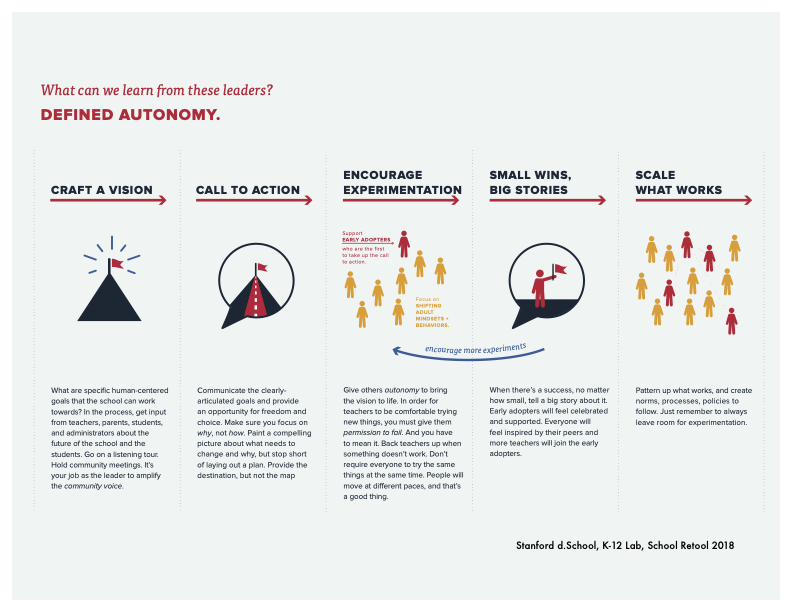
Shared purpose and vision — but not a set roadmap. Educators need a compelling north star that anchors their experimentation: the big, audacious learner outcomes they aspire to, such as those described by the Deeper Learning framework (Hewlett Foundation, 2013). Without shared direction, individual experiments remain uneven, and organizations lose the coherence they need to eventually shift toward something better. This is what School Retool calls "defined autonomy": articulating clear goals while giving people genuine freedom to explore paths toward them (School Retool, n.d.; Marzano & Waters, as cited in School Retool, n.d.). Paint a compelling picture of why this matters and what you're ultimately trying to achieve for students — then trust educators to figure out the how.
Divergent experimentation — not uniform adoption. At this stage, the field needs many educators trying many different things. We don't yet know what works, for whom, in which contexts. That's not a problem to solve before we start; it's the nature of early-stage innovation. Divergent experimentation positions in-house educators as experts whose ideas are as valuable as those of the external experts in the field whose insights tend to dominate PD during the scaling phase. Research on bottom-up innovation in education consistently shows that "innovative ideas tend to come from a relatively small number of well-networked or designated personnel at the local level, and they spread because other teachers have relationships with these insider innovators" (Wolfe, 2026, p. 8). This means encouraging and protecting experimentation within their school or organization — even when it feels inefficient — and creating the networks that allow insights to travel.
Coordinated effort to break silos. Divergent experimentation only becomes collective learning when there are mechanisms to share what's being tried, what's working, and what isn't. Without coordination, insights get lost, innovations remain in pockets, and the field stagnates. Grunow, Park, and Bennett (2024) describe this as the heart of improvement science: collective learning requires "groups of people with diverse expertise to come together, surface and test tacit assumptions, and generate new shared understandings about how to make systems better" (p. 132). In the context of AI, this means creating genuine, ongoing opportunities for educators to share their experiments across classrooms, schools, and systems — not just at annual conferences or end-of-year showcases. As Chris Unger (2026) observes, the thoughtful district in Iowa may have built something remarkable — but the superintendent in Georgia has never heard of it. "That is a knowledge diffusion problem"... and it is entirely solvable — but only if we invest in the connective structures that allow knowledge to travel across educators in real time (para. 15).
Real-time, iterative feedback. Educators trying AI tools in their classrooms need rapid feedback loops to know whether something is working — for whom, under what conditions, at what cost. The improvement science tradition offers a useful frame here: Plan-Do-Study-Act (PDSA) cycles, which allow teams to test changes on a small scale, study what happens, and adapt before scaling (Grunow et al., 2024). "Two of the most useful pieces of advice for those interested in taking on an improvement approach," Grunow et al. note, "are: get started before you are ready, and learn your way into improvement" (p. 5). The goal is not to get it right the first time; it's to learn quickly enough to get it right eventually.
“Get started before you are ready, and learn your way into improvement.”
— Alicia Grunow, Sandra Park, & Brandon Bennett
Permission — and infrastructure — to fail. Perhaps most importantly, educators need genuine, organizational permission to fail. Research on innovation in schools is unambiguous on this point: "Decades of emphasis on standardized test scores have conditioned educators to avoid failure" and the resulting risk-aversion is one of the most significant barriers to productive innovation (Wolfe, 2026, p. 9). This is a culture and leadership issue as much as a PD design issue. When school leaders celebrate early adopters, share stories of experiments that didn't work (and what was learned), and protect teachers from punitive consequences for trying new things, they send a message that learning from mistakes is not just permitted — it's valued (School Retool, n.d.). The Small Wins Dashboard extends this notion into progress-tracking: it captures evidence of the learning that occurred from things that didn't work (in addition to things that did), framing lessons learned as Small Wins and progress.
Toward Transformed Schools and Outcomes
When educators are pushed through "best practice" AI PD before best practices exist, several things happen: the PD feels disconnected from reality, trust in professional learning erodes, and the rich diversity of educator insight that could actually advance the field gets suppressed in favor of compliance with premature norms.
Wolfe's (2026) framework for bottom-up innovation is instructive here. Drawing on studies of school reform, she finds that innovations are far more likely to take hold when they "align with teachers' already-held beliefs" and can "be used immediately or easily added to existing methods" (p. 10). She also finds that specific training or formal PD "may not be as strong a catalyst as organic networks" — innovations spread most reliably through the trusted peer relationships educators already have, not through top-down mandates (p. 8). This is a blueprint for how to design AI professional learning right now: anchor it to educators' values, make it more teacher-driven (Darling Hammond et al., 2017), make it practically useful for tomorrow's class, and invest deeply in peer-to-peer exchange.
It also means letting go of uniformity. Not every educator needs to be experimenting with the same AI application in the same way at the same time. People will move at different paces, and that is not only acceptable — it may be exactly what a healthy innovation ecosystem requires. As Grunow et al. (2024) remind us, "if the team is not learning, something is wrong" (p. 6). The measure of good AI PD right now isn't whether everyone is using the same tool the same way. It's whether everyone is learning.
This is exactly the kind of professional learning sideby was designed to support. sideby's peer-to-peer learning model creates structured, one-to-one conversations that help educators share what they're experimenting with, reflect on what they're seeing, and build knowledge together without requiring anyone to already have the answers. sideby positions every educator as both a learner and a knowledge contributor, with a commitment to transformational professional learning at its foundation.
The future of AI in education will be shaped by educators learning together through shared experimentation, real classroom practice, and the connective infrastructure needed to surface and spread what works.
References
Darling-Hammond, L., Hyler, M. E., & Gardner, M. (2017). Effective Teacher Professional Development. Learning Policy Institute. https://learningpolicyinstitute.org/product/effective-teacher-professional-development-report
Grunow, A., Park, S., & Bennett, B. (2024). Journey to improvement: A team guide to systems change in education, health care, and social welfare. Rowman & Littlefield.
School Retool. (n.d.). Creating change in schools. [Creative Commons Attribution 4.0 International License.]
The William and Flora Hewlett Foundation. (2013, April). Deeper learning defined. https://hewlett.org/library/deeper-learning-defined/
Unger, C. (2026, April 11). From the "Jagged Frontier" to the "Fractured Frontier": The Real Challenge of AI in K12. The AI Frontier [Substack]. https://arevolutionineducation.substack.com/p/from-the-jagged-frontier-to-the-fractured?r=di8ui
Wolfe, R. E. (2026, January). Can't get there from here: A framework for the start, spread, and scale of bottom-up innovation in education. Hoover Institution, Stanford University. https://www.hoover.org/research/cant-get-there-here-framework-start-spread-and-scale-bottom-innovation-education
TL;DR
We're in an emergent AI experimentation phase — not a best-practice scaling phase. These are fundamentally different moments that call for fundamentally different professional learning.
Most AI professional development is designed for the wrong moment: it mirrors how we scale known practices, but we don't yet have known best practices to scale.
Effective PD at this stage requires shared vision, divergent experimentation, coordinated learning, real-time reflection, and genuine permission to fail.
sideby's peer-to-peer learning model is built for exactly this moment.